R package for gender prediction based on first names
The package uses genderize.io API to predict gender from first names extracted from text vector. The accuracy of prediction could be control by two parameters: counts of a first name in the database and probability of prediction.
README, BugReports and development repository on GitHub: https://github.com/kalimu/genderizeR
The package webpage on CRAN:
http://cran.r-project.org/web/packages/genderizeR
Article & Citations:
When using the genderizeR R package in your work, please cite also the article:Kamil Wais, Gender Prediction Methods Based on First Names with genderizeR, The R Journal,Vol. 8/1, Aug. 2016, https://journal.r-project.org/archive/2016-1/wais.pdf
@article{RJ-2016-002,
author = {Kamil Wais},
title = {{Gender Prediction Methods Based on First Names with
genderizeR}},
year = {2016},
journal = {{The R Journal}},
url = {https://journal.r-project.org/archive/2016/RJ-2016-002/index.html},
pages = {17--37},
volume = {8},
number = {1}
}
Abstract:
In recent years, there has been increased interest in methods for gender prediction based on first names that employ various open data sources. These methods have applications from bibliometric studies to customizing commercial offers for web users. Analysis of gender disparities in science based on such methods are published in the most prestigious journals, although they could be improved by choosing the most suited prediction method with optimal parameters and performing validation studies using the best data source for a given purpose. There is also a need to monitor and report how well a given prediction method works in comparison to others. In this paper, the author recommends a set of tools (including one dedicated to gender prediction, the R package called genderizeR), data sources (including the genderize.io API), and metrics that could be fully reproduced and tested in order to choose the optimal approach suitable for different gender analyses.
Testimonials:
From the peer-reviews:“[…] In this paper, the authors provide methods and an R package for gender prediction based on a set of names. This comes an opportune time, given the increased number of studies that require gender identification. As someone who has to do this for my own studies, I immediately see value in this kind of package and know of many colleagues who would also use this package.”Other testimonials:
It is easy creating a highcharts using highcharter, an amazing library as genderizeR, the one I use to obtain gender names. I like them a lot. Visualizing the Gender of US Senators With R and Highmaps
I also used a very interesting package called genderizeR, which makes gender prediction based on first names The Gender of Big Data
Following this discussion on Finnish names, I came across the fantastic genderizeR package, which looks into an online database to determine gender from names in several languages. [source link]
I’m a Data Scientist working for a company on the automotive industry. I stumbled upon the genderizeR package while looking for a solution that would allow me to complete missing data, present on our databases. Sometimes some people forget to fill out their honorific titles (e.g. Mrs.), or they’re transcribed poorly from paper-based documents. With this package, I’m able to not only correct those mistakes, but also to complete the missing data to provide stronger statistical value to my work. All this can be done automatically, directly in R. I personally thank Dr. Kamil Wais for helping me with some features that are to be implemented in a future version of the package.
Carlos
Without this package, I never would have been able to implement the algorithm I needed to assess gender balance in syllabi, since RShiny doesn’t work well with https. Thanks so much for making it. It’s really great and makes using the genderize.io API so much easier.Jane
Jane is the author of a Shiny app, which is an interesting use case for the genderizeR package:
How Gender-Balanced is Your Syllabus? One of the explanations for the gender citation gap is that syllabi are disproportionately male. Thus, when students begin conducting their own research, most of their exposure has been to male researchers. Yet even well-meaning instructors may find that they have difficulty assessing how gender-balanced their syllabi really are. Counting is tedious and prone to human error, and instructors may not know the gender identities of all the authors they cite. This tool aims to help with that, by automating the process of evaluating the (probabilistic) gender of each name and then providing an estimate of what percentage of the authors on a syllabus are women.
I am glad that the package can be helpful for so many applications.
Examples of applications
- Fell, C.B. & König, C.J. Is there a gender difference in scientific collaboration? A scientometric examination of co-authorships among industrial–organizational psychologists, Scientometrics (2016) 108: 113.
- How Diverse is Your Syllabus?
- Visualizing the gender of US senators with R and Highmaps
- Women in Orchestras
- The Gender of Big Data
Collaboration
Feel free to comment or contribute in any way! Let me know if you are using the genderizeR package in your work or if I could help you in your research or commercial project.
Speed Test
A few people have been asking about the speed of the package, so I have done some speed test using the latest version of the genderizeR package.
Without any parallel programming I managed to check 108 023 unique terms through genderize.io API and it took 45 minutes (2 395 term per minute).
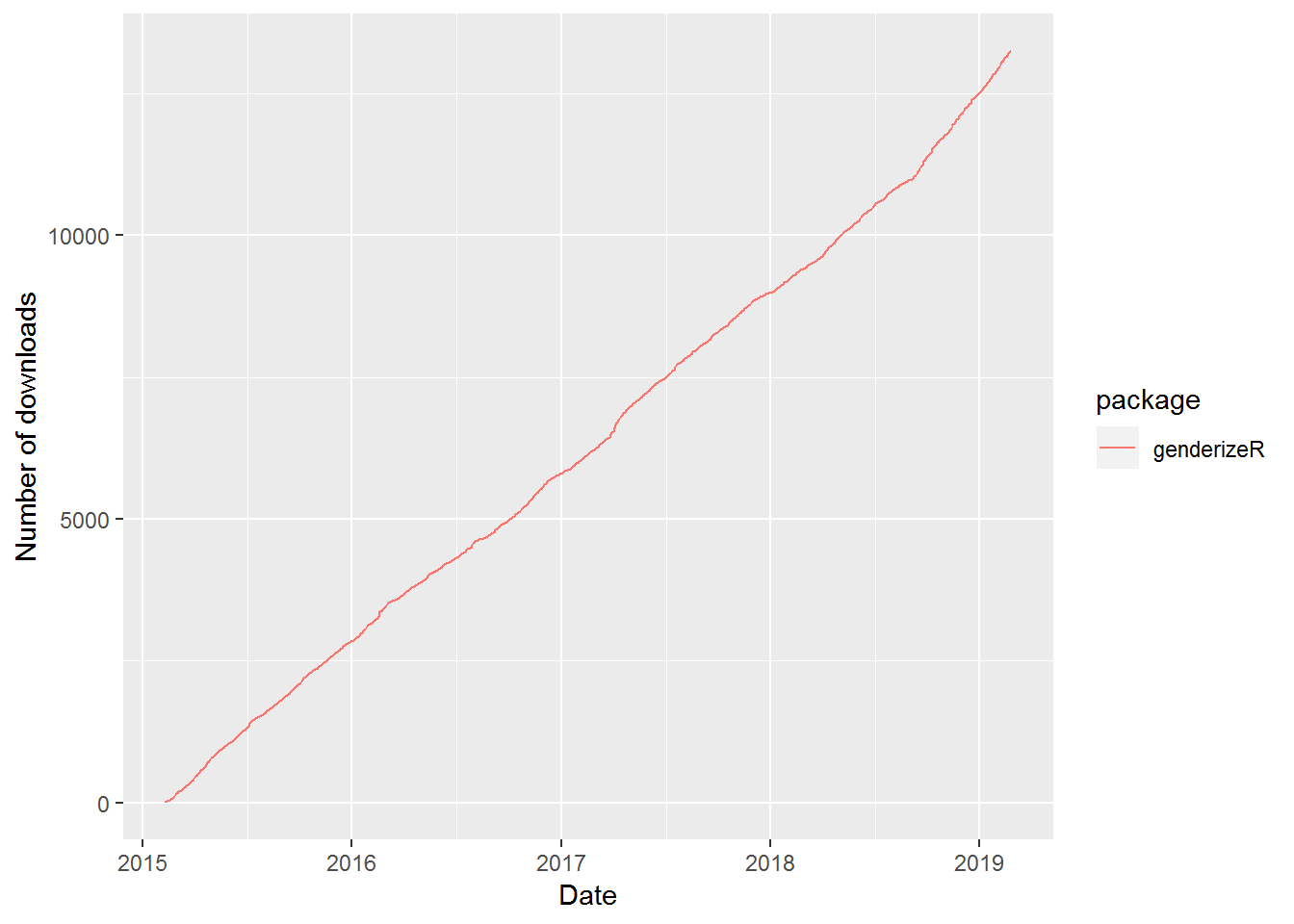
Package downloads
(from CRAN RStudio mirror)